
Si humanización fue la palabra de 2018, seguramente big data o inteligencia artificial sean las protagonistas absolutas de 2019. De hecho, hace unos días hablamos de las tendencias que está desarrollando la inteligencia artificial (y el machine learning, que podríamos decir que son familia).
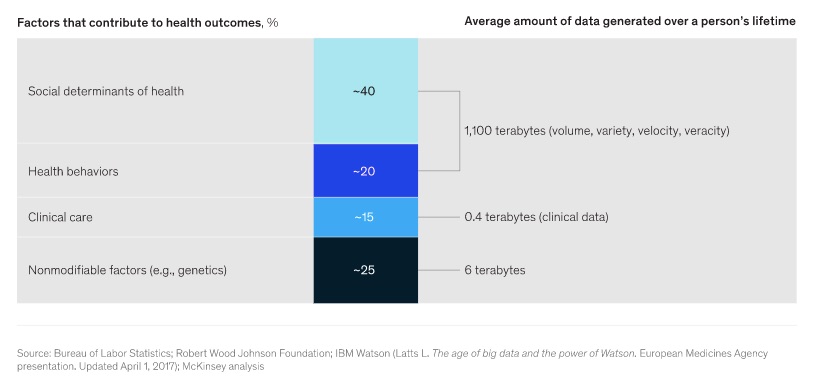

Uno de los principales miedos es el tema de la privacidad. Los datos relacionados con estilos de vida son muy útiles para el marketing, y por eso Google y otro tipo de webs ofrecen sus servicios gratis, porque a cambio les damos ese gran volumen de datos sobre nuestra vida y entorno social. De hecho, algunos autores ya se preguntan si nuestras leyes de privacidad están preparadas para ello, como cuentan en este artículo publicado en Catalyst.
Una solución interesante, que ya comentamos en el blog hace unos meses, es integrar la información social y de estilos de vida de cada persona en su propia historia clínica. De esta forma, se le otorga un nivel de protección mayor. En Estados Unidos se ha elaborado un protocolo de recogida de parte de esta información (preguntando al paciente) conocido como PRAPARE. Sin embargo, ¿y el resto de la información? ¿cómo podemos recogerla e incorporarla? En este artículo de 2019plantean algunas ideas y casos prácticos muy interesantes, como se ve en esta gráfica.
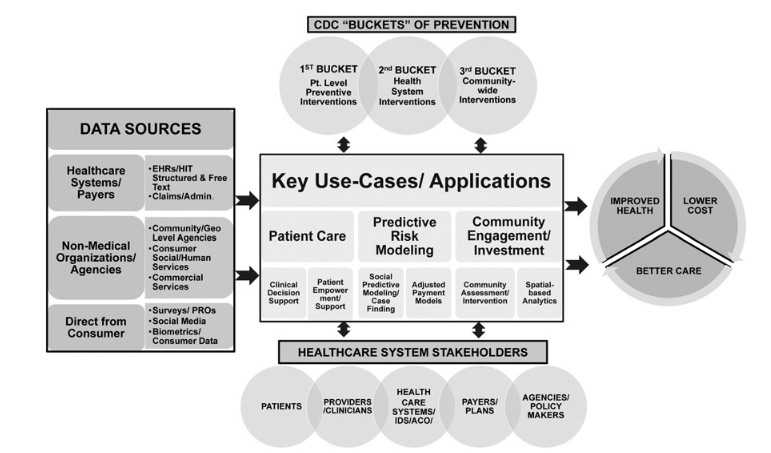
Dos cosas finales:
– Un reciente libro sobre el papel de los datos y de la inteligencia artificial en el entorno sanitario es “Deep medicine“, de Eric Topol.
– Un zasca que hemos leído en Microsiervos sobre el uso del ADN: ante un artículo sobre el uso de la información genética para saber si un bebé obtendrá un doctorado o no, alguien respondió “Esto ya puede hacerse sabiendo el código postal“.



Gran entrada como siempre, maestro! Una referencia que puede ser interesante es el trabajo de Claus Nielsen desde una perspectiva de paciente https://digitalenlightenment.org/system/files/230517_nordic_geoforum_ab_short.pdf con la Data for Good Fundation.
Muchas gracias por el gran post, as usual. Tenemos que relacionar los datos sociales con los datos clinicos, como ya estan haciendo en Estados Unidos